
RESEARCH HIGHLIGHTS
Our research highlights serve as a collection of feature articles detailing recent scientific achievements on GCS HPC resources.
JSC Researcher Improves Deep Learning Training
Research Highlight –
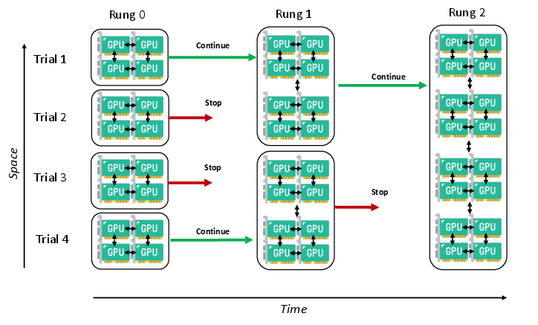
Marcel Aach focused his PhD thesis on how to improve AI training. The chart illustrates the crux of
his work: Aach designed a way to shift GPU resources toward the most promising training instances. Image credit: Marcel Aach.
Within the expanding field of artificial intelligence (AI), computer scientists continuously develop new AI models that boost scientific, commercial, and personal productivity. The need for more tailored models is rapidly growing, so scientists must optimize training these models that are increasingly demanding more computational resources. Specifically, the training of large, complex neural networks used for deep learning tasks like advanced image classification or drug design is becoming prohibitively expensive, which means researchers are reliant on the world’s most powerful computational resources to continue to develop new, powerful models.
Marcel Aach has focused his academic and professional experiences on one aspect of AI training that has big implications for improving the efficiency of training large models for deep learning tasks – optimizing the so-called hyperparameters that control the accuracy and speed of models and their training. In his recently published doctoral thesis, Aach used Julich Supercomputing Centre’s (JSC’s) JUWELS Booster supercomputer to develop a new hyperparameter optimization (HPO) method to train the next generation of AI models more efficiently, specifically by progressively shifting computational resources toward the most important training tasks. “For a long time, researchers have known that if you want to improve an AI models performance, you have to increase the amount of training data you have,” he said. “At this point, though, it means that training state-of-the-art AI models requires massive amounts of training data and needs intensive computational resources. Working on national and European research projects at JSC, I realized that HPO is a topic that basically unites everyone who builds machine learning models, no matter the research domain.” The key advantage of HPO is that, when applied effectively during training, it significantly improves efficiency and enhances the quality of resulting AI models without requiring additional data or computational resources.
Hyperparameter optimization speeds up training with help of GPUs
Aach first studied AI through his experiences optimizing high-performance computing (HPC) simulations to run in parallel. With this method, the calculations of a specific simulation are distributed across many computer cores, and the results are shared efficiently across a supercomputer. As Aach became more interested in neural networks, he applied his HPC experience to AI training and realized that exploiting parallelism when training a deep learning model was essential to improve efficiency. He likened hyperparameters to knobs and levers that scientists can set before training a model. They determine the speed, specificity, and level of detail, among other aspects, that researchers use in neural network training. “For these large models, it is essential to pick good hyperparameters from the beginning, because you do not want more of these costly GPU trainings than absolutely necessary,” he said. “We want to make sure we’re helping build the best models, but hopefully with one or a couple of training runs rather than dozens.”
With his access to JUWELS Booster and experience optimizing large-scale computational codes, Aach knew he could use the system’s 3,744 GPUs to increase parallelism in two ways: by testing different hyperparameters for a model and by completing test runs as efficiently as possible. He noted that no matter what the training goal is, all scientists who are training for deep learning tasks must evaluate a model’s performance on a variety of scales and with various hyperparameters. If these training runs are running in parallel, scientists can more quickly determine the best performing hyperparameters for the main model training. To more efficiently complete these test runs, researchers must also ensure that their models are optimized to run across many more GPUs than in the past.
While these two areas of parallelism already improve efficiency, Aach wanted to develop a technique that could further improve HPO by shifting computational resources to focus on the most-promising models. “For my doctoral research, I developed a way for us to study the various test runs of a neural network, focus on each iteration’s accuracy or error rate, and then shift GPUs from the networks that were not performing well to the models that were performing the best,” he said. “So, we mixed these two ways of parallelism and ultimately got results in a faster way by consolidating resources for the best models.” Aach tested his method on a variety of deep learning applications, ranging from computational fluid dynamics and remote sensing to computer vision benchmarks and data analysis tasks using the OpenML machine learning platform. Results showed that his method improved training efficiency across all applications.
JSC's exascale resources support larger-scale model training
With his PhD successfully defended, Aach is next shifting into a postdoctoral research position at JSC to continue focusing on HPO. His work comes at an opportune time, as JSC just inaugurated JUPITER, its next generation supercomputer that will be Europe’s first exascale system. JUPITER not only represents a more than ten-fold increase in computing power over JUWELS, but also has roughly 24,000 next-generation NVIDIA Hopper GPUs — offering a massive performance boost for AI model training. “We evaluated this method on petascale computing systems like JUWELS, using roughly 1,000 GPUs, several terabytes of training data, and a few million training parameters,” Aach said. “With the arrival of JUPITER, we can scale that up to a few hundred terabytes of training data and billions of parameters being trained for a given neural network. I’m looking forward to working at JSC and seeing how my method performs when we bring it to this scale.”
-Eric Gedenk
You can read Aach's full thesis at: https://opinvisindi.is/handle/20.500.11815/5293
Funding for JUWELS was provided by the Ministry of Culture and Research of the State of North Rhine-Westphalia and the German Federal Ministry of Education and Research through the Gauss Centre for Supercomputing (GCS).
This article originally appeared in the autumn 2025 issue of InSiDE magazine.