
Artificial Intelligence and Machine Learning
RedMotion: Intelligent Motion Prediction for Autonomous Vehicles
Principal Investigator:
Dr. Andreas Lintermann, Dr. Marcel Aach
Affiliation:
Forschungszentrum Jülich GmbH, Jülich Supercomputing Centre, Jülich, Germany
Local Project ID:
genai-ad
Date published:
Summary:
RedMotion: Intelligent Motion Prediction for Autonomous Vehicles
Autonomous vehicles must predict the motion of other road users within fractions of a second in complex urban environments with hundreds of lanes, traffic lights, and vehicles. RedMotion addresses this challenge through a novel transformer architecture that learns augmentation-invariant and redundancy-reduced descriptors of road environments. By compressing up to 1,200 local environmental features into exactly 100 compact tokens through self-supervised learning, RedMotion achieves efficient and accurate motion prediction. Training on millions of traffic scenes from the Waymo and Argoverse datasets required extensive parallel computations on the GPU nodes of JUWELS Booster.
The Challenge
Autonomous vehicles must predict within fractions of a second where other road users will move. This prediction is particularly challenging in complex urban environments with many vehicles, pedestrians, and changing traffic rules. Traditional approaches struggle with information overload: How do you process data about hundreds of lanes, traffic lights, and other vehicles without losing important details?
Our Solution: RedMotion
FZI has developed RedMotion, a novel method that learns to extract only the truly important information from the road environment. The system uses two innovative "redundancy reduction" mechanisms:
1. Redundancy Reduction: RedMotion distills up to 1,200 local information elements (e.g., overlapping lanes, closely clustered vehicles) into exactly 100 compact "RED tokens" -- similar to how a human reduces a complex traffic situation to its essential aspects.
2. Self-Supervised Learning: The model automatically learns which features are important by viewing the same traffic scene from slightly different perspectives and developing robust, invariant representations through a Barlow Twins loss function.
The Architecture
RedMotion consists of three principal components (Figure 1):
- A trajectory encoder converts the past one second of an agent's motion into an embedding sequence
- A road-environment encoder processes lane segments, other agents, and traffic-light states through local-attention transformer layers, then uses a parallel decoder to distill these features into the 100 RED tokens
- A lightweight cross-attention module fuses all information with linear complexity, avoiding the quadratic cost of standard attention mechanisms
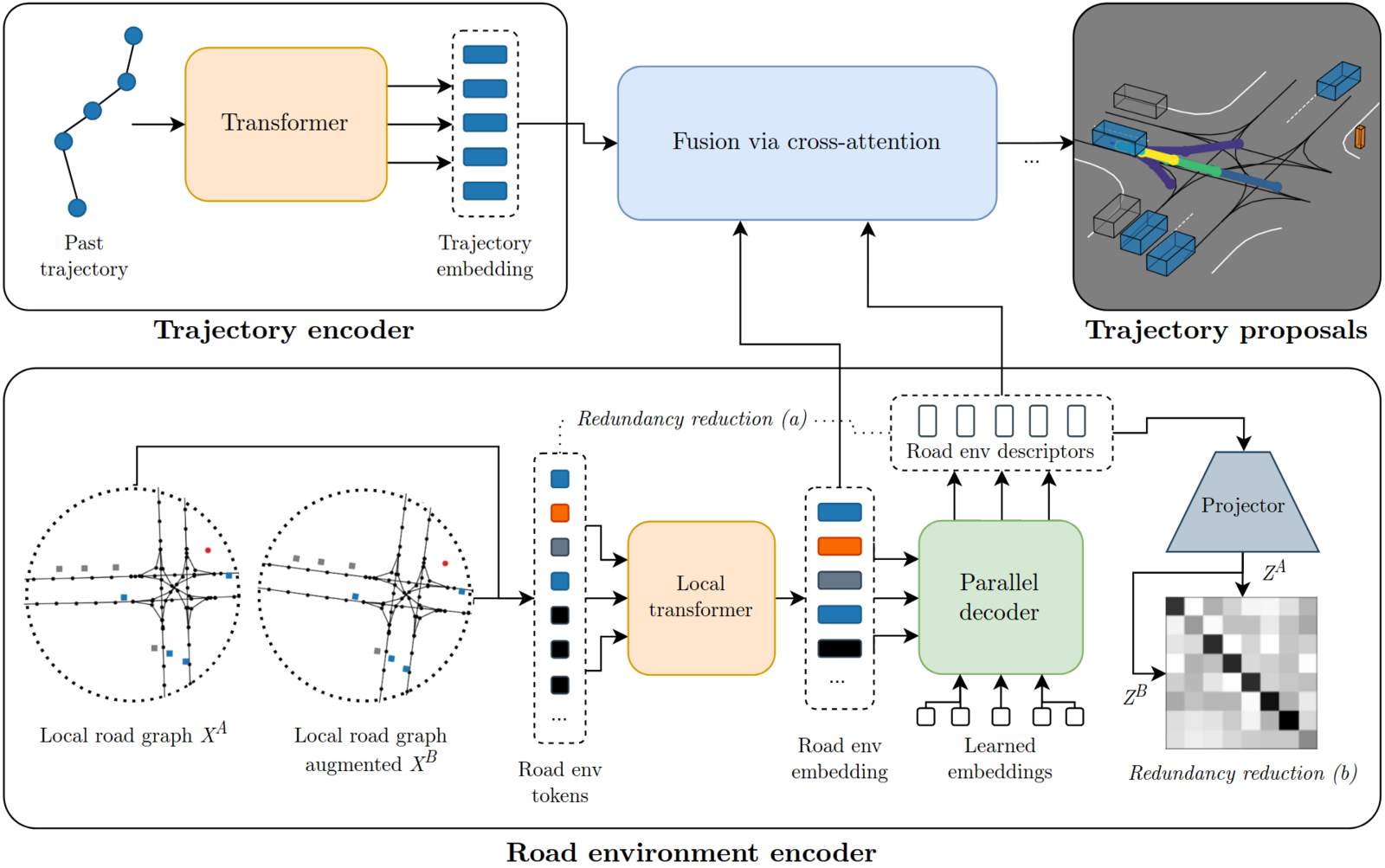
Figure 1: RedMotion architecture showing the trajectory encoder, road environment encoder with local and global (RED) tokens, and the two redundancy reduction stages.
Why Supercomputers?
Developing RedMotion required massive computational power:
- Large datasets: The model was trained on millions of real traffic scenes from the Waymo Open Motion Dataset (WOMD) and Argoverse 2 Motion Forecasting dataset (AV2)
- Complex architecture: The transformer-based neural networks with their millions of parameters require parallel computations across many GPUs simultaneously
- Extensive experiments: Over 200 training runs were needed to find optimal configurations – each run took 100 epochs on 32 GPU nodes of JUWELS Booster
The ability to run multiple experiments in parallel on JUWELS was crucial for exploring different hyperparameters, training strategies, and architectural variants.
Results and Impact
RedMotion achieves competitive prediction accuracy while being significantly more efficient than existing methods. By processing the road environment in a structured, compact form with fixed-size representations, it enables:
- Scalability: Performance remains consistent regardless of scene complexity
- Efficiency: Linear computational complexity through the cross-attention fusion mechanism
- Robustness: Augmentation-invariant features that generalize across different viewpoints and conditions
The research results were published in the prestigious "Transactions on Machine Learning Research" (2024) and provide important foundations for safer autonomous driving systems. The learned representations are reusable for various downstream tasks beyond motion prediction, making RedMotion a versatile building block for autonomous vehicle perception systems.
Reference
Royden Wagner, Omer Sahin Tas, Marvin Klemp, Carlos Fernandez, and Christoph Stiller, RedMotion: Motion Prediction via Redundancy Reduction, Transactions on Machine Learning Research, 2024.