
ASTROPHYSICS
DataParallel ECHO: Heterogeneous Programming Applied to High-Energy Astrophysics
Principal Investigator:
Dr. Salvatore Cielo
Affiliation:
Bayrische Akademie der Wissenschaften, Garching, Germany
Local Project ID:
pn49xu
HPC Platform used:
SuperMUC-NG of LRZ
Date published:
Abstract
Numerical sciences are experiencing a renaissance thanks to the spread of heterogeneous computing. The SYCL open standard unlocks GPGPUs, accelerators, multicore and vector CPUs, and advanced compiler features and technologies (LLVM, JIT), while offering intuitive C++ APIs for work-sharing and scheduling.
The project allowed for the kick-off of DPEcho (short for Data-Parallel ECHO), a SYCL+MPI porting of the General-Relativity-Magneto-Hydrodynamic (GRMHD) OpenMP+MPI code ECHO, used to model instabilities, turbulence, propagation of waves, stellar winds and magnetospheres, and astrophysical processes around Black Holes, in Cartesian or any coded GR metric. Thanks to SYCL Unified Shared Memory (USM) data reside permanently on the device, maximizing computational times.
____________________________________
Report
Numerical experiments are paramount for astrophysics, as the modelled systems feature physical processes, sizes and timescales which cannot be investigated experimentally, as well as complex interactions often impossible to describe analytically. This has led to the creation of countless simulation codes, based on various hydrodynamics and gravity schemes. These numerical methods are highly computationally- and memory-intensive. Some codes are being developed and maintained for multiple decades, and thus it is of vital importance to both tune and optimise them for new architectures, and to modernise the codebase to conform to current best practises of the field.
Computing centres such as the Leibniz Supercomputing Centre (LRZ), part of the Gauss Centre for Supercomputing (GCS), devote a large part of their resources and specialised support to such ends, also bridging the gaps between science users, HPC developers and hardware/software vendors. The DPEcho code is the result of such a collaboration.
_____________________________________
The ECHO GR-MHD code introduced a general 3+1 Eulerian formalism, in a generic space-time metric, allowing for coupling with any Einstein’s equations solver. ECHO implements conservative finite-difference scheme and novel treatment of the induction equation make it particularly accurate, efficient, versatile, and robust in the modelling of interstellar turbulence, and astrophysical processes around highly magnetized and compact objects.
ECHO featured already an HPC-optimized version, named 3D-HPC, written in Fortran language, MPI+OpenMP parallel, and able to run on multicore CPUs. Yet to unlock the computing power of accelerators, the migration to SYCL/C++ was deemed the best strategy. The main challenge of the porting was to introduce for the first time a GPU layer, in the new programming language, while adopting essentially the same algorithmic choices (compatibly with the language switch).
______________________________________
The choice of SYCL presented several advantages that facilitated the task: unlike proprietary programming models such as NVIDIA’s CUDA, SYCL is a crossplatform layer, not limited to a single vendor’s hardware: this alleviates the need for redundant development, maintenance and coordination of multiple GPU ports. At the same time, SYCL allows for more fine-granular control than other, more general programming methods such as OpenMP offloading.
In particular, the most notable features of DPEcho are:
- most methods and algorithms of ECHO 3D-HPC (the most notable exception being the UCT divergence-cleaning);
- CMake integration for structured compilation;
- simplified device selection with SYCL device aspects;
- the use of Unified Shared Memory (USM) for a more familiar and efficient programming mode for the ease of science users;
- portability to most common CPUs and GPUs with no code change, including good performance on heterogeneous hardware.
The latter can easily be achieved thanks to the Intel LLVM free compilers, or the free-to-use plugins developed by Codeplay for use with Intel’s oneAPI toolkit which enable the generation of code for NVIDIA’s or AMD’s GPUs without the need to compile LLVM oneself.
Thus, after the kick-off phase on SuperMUC-NG, it was possible to execute DPEcho using hardware by all major vendors, on the Intel Data Center GPU Max Series (formerly Ponte Vecchio), the NVIDIA H100 and the NVIDIA A100, the AMD Instinct MI100, and on a number of Intel CPUs.
____________________________________
Fig. 1: Test problem: Alfvén GR-MHD wave propagation in Cartesian Coordinates
____________________________________
For the evaluation, we setup a representative GR-MHD test – the propagation of plane-parallel Alfvén waves (magnetic waves powered by magnetic field tension) along the 3D diagonal of a cubic simulation box (Figure 1), with periodic boundary conditions along all directions. Alfvén waves are dispersionless, thus especially suitable for testing the accuracy of numerical schemes. We aim at efficiently filling the GPU memory and execution units, in order to minimise the relative SYCL initialisation and scheduling overhead, and test production-ready configurations. We therefore perform a scaling test over the problem size (at different resolutions) from 64 to 512 grid elements per side. Given the relatively high resolution we achieve, we make the test more demanding by fitting multiple wave creases along each side. Performance measurements are presented in Figure 2. For tile-able GPUs, we show both single-tile (ST in the figure) and implicit scaling (i.e. using the full hardware, IS in the figure) results. Besides a predictable variability due to this fact, all the tested hardware brings considerable speedup over the pure CPU runs. Despite the minimal data transfer granted by the USM and malloc device, all GPUs reach a plateau of performance only for larger boxes (>192ˆ3), due to scheduling overhead and device utilisation.
____________________________________
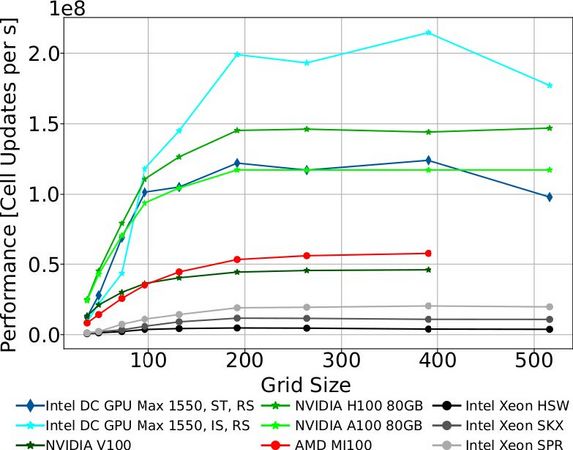
Fig. 2: Performance scaling with problem size on heterogeneous hardware by Intel, AMD and NVIDIA
____________________________________
In a further test, we evaluated the weak scaling behavior of DPEcho on multiple GPUs. We ran configurations ranging from one to 192 nodes of the upcoming cluster SuperMUC-NG Phase 2, a cluster comprising 236 nodes with four Intel Data Center GPU 1550 accelerators each. The results, given in Figure 3, show that DPEcho can scale effortlessly to enable larger-scale simulations.
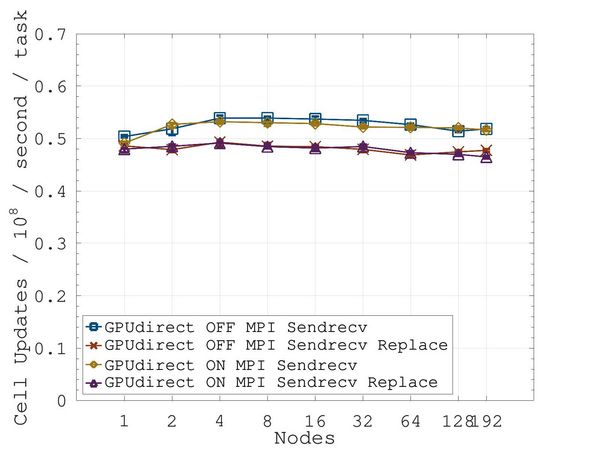
Fig. 3: Weak scaling tests on SuperMUC-NG Phase 2
____________________________________
DPEcho is freely available on GitHub for the HPC and astrophysics community. It constitutes an excellent example of SYCL benchmarks for heterogeneous hardware, and very representative of typical astrophysics workload.
Bibliography
[1] DPEcho on GitHub
[2] DPEcho: GR with SYCL for the 2020s and beyond on Intel.com
[3] DPEcho SYCLcon23 proceedings
[4] The ECHO code