
RESEARCH HIGHLIGHTS
Our research highlights serve as a collection of feature articles detailing recent scientific achievements on GCS HPC resources.
Research Snapshot: University of Wuppertal Research Team Uses Jülich Supercomputing Centre's HPC Resources to Reduce AI Uncertainty
Research Snapshot –
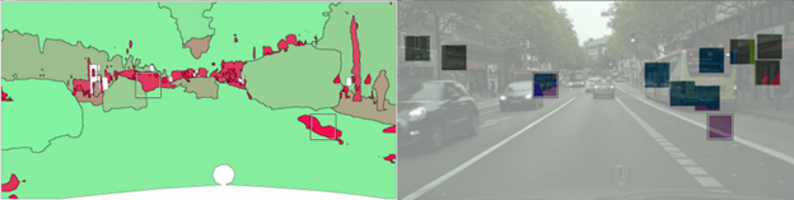
A visualization of an active learning method for the semantic segmentation of camera images with street scenes. Left: an uncertainty quantification (red color represents high uncertainty of a given AI, green low uncertainty). Right: Image regions selected for labelling based on the uncertainty quantification, presented to the AI after the fact such that the latter learns from it. Image credit: Matthias Rottmann
In the last decade, artificial intelligence (AI) has gone from science fiction fodder and early experiments in computer language processing to a key technology remaking industries from transportation and energy to media and the arts. While AI applications quickly made their marks on many aspects of life, perhaps no other use case has excited and worried policymakers, industry experts, and the public like the idea of autonomous-driving cars.
Computer scientists understand how to program a vehicle to drive under ideal, predictable conditions: a train driving down the same pattern on a track, or even a car driving around in a closed environment. Much more difficult, however, is preparing those vehicles for how to react to new information or objects that they have not “seen” before. For researchers like Dr. Matthias Rottmann at the University of Wuppertal, training AI-governed systems to make the right choice when they face the unknown requires the help of high-performance computing (HPC) resources.
“If you want to train an AI application for situations where you don’t have real, organic data, or you want to use less data to train an application, you are going to have to pay your tab with a lot of computing power,” Rottmann said. He and his team have been using the GPU-equipped JUWELS Booster supercomputer at the Jülich Supercomputing Centre (JSC)—one of the three centres that comprise the Gauss Centre for Supercomputing (GCS)—to work on improving computational decision making that can be applied to real-world applications like autonomous driving.
Think for yourself
Artificial intelligence applications often learn how to perform a task by being shown millions or billions of images, word sets, minutes of video footage, or another input. Researchers ask the program to distinguish one object from another, pick out anomalies in a situation, or find a pattern in a large, unstructured dataset. When training an application in this manner, researchers give the program negative feedback for each wrong answer, helping sharpen the application’s ability to make the right choice in the future. While this approach is effective, it can become prohibitively expensive in time and resources when trying to train an application for an extremely large set of possibilities.
“In active learning, we train models over many iterations, with the model flagging objects it is unsure of, requesting feedback, and acquiring a bit more information that can be used for training in the process,” he said. “For this work, I know that I need to run thousands of these experiments, so I need HPC.”
Among other research focuses, Rottmann’s team works on improving a different machine learning approach, what he referred to as active learning, which allows the application to flag objects it is unsure of rather than waiting for negative feedback. For Rottmann, working on improving active learning ultimately addresses two of his primary research motivations—how to lower the computational demands for training an AI model and how to progress AI research more efficiently. “With regular, supervised AI training, the application is almost like someone watching TV with labels in the subtitles—they are consuming many thousands of labelled images passing by. While I am motivated to see advancements in autonomous driving and other applications, my research interest is more fundamental than that: why does AI need to see 10,000 images of cats and dogs before it is able to distinguish them?”
Using JUWELS, the team was able to use active learning to improve an application’s performance during semantic segmentation—the process of an AI application dividing up a training image into pixels and labelling each one based on what it thinks the objects in the image are. The team has a pre-print journal article in review and has presented its findings during the 18th International Joint Conference on Computer Vision, Imaging, and Computer Graphics Theory and Applications in 2023.
For Rottmann and his team, ushering in the AI revolution in a safe, transparent, and inclusive manner requires a groundswell of academics working on complex, foundational challenges that come with adopting AI into these important—and occasionally dangerous—societal spaces. While many large, foundational AI models are owned by private companies, Rottmann believes that an equitable AI future will be balanced out by open-source initiatives that ensure these technologies are available for everyone.
Rottmann and his team are now focusing more on the key component for successful AI programming: data. “I am moving more toward studying data-centric AI,” Rottmann said. “Selecting data that matters for a given application, improving data quality by using AI to detect label errors during training, and finding new sources of data as AI trainers face more challenges in sourcing new, high-quality data. I also want to work more with these foundational models and explore new applications for my methodology outside the realm of autonomous driving tasks.”
-Eric Gedenk