
NEWSFLASHES
Extreme-Scale HPC Expert Talks Next-Generation Architectures, Promises and Challenges of Exascale
Newsflash 13/2019 –
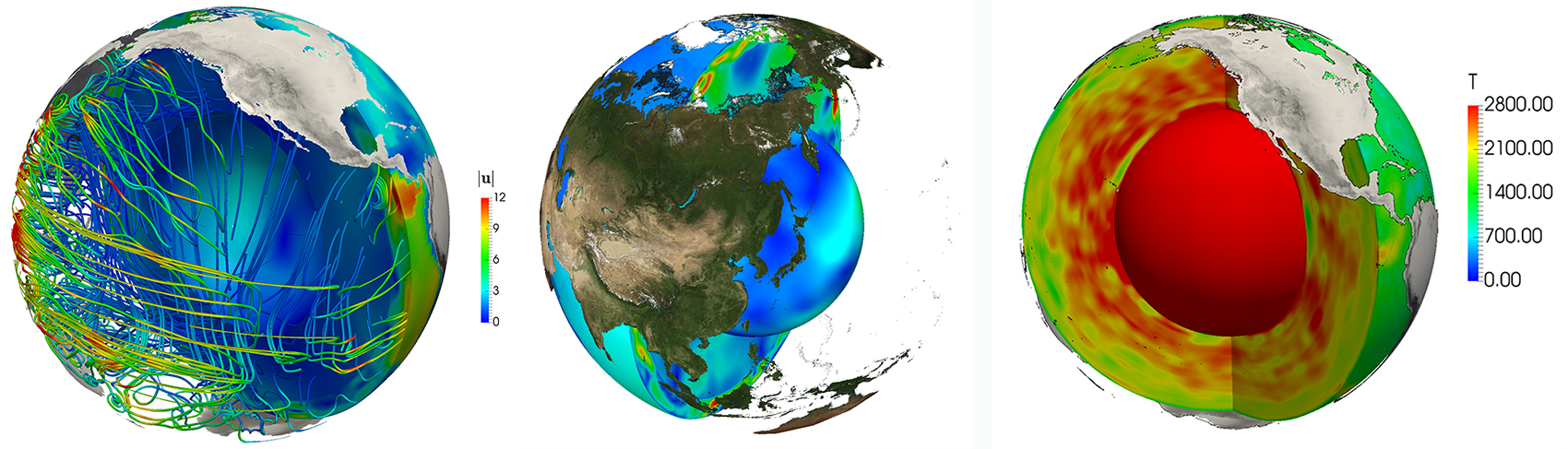
Prof. Rüde has recently collaborated with numerical analysts from the Technical University of Munich (TUM) and geophysicists from the Ludwig Maximillians University Munich (LMU) in using GCS high-performance computing (HPC) resources at the Leibniz Supercomputing Centre (LRZ), the Jülich Supercomputing Centre (JSC), and the High-Performance Computing Center Stuttgart (HLRS). His collaborations have focused on developing new codes for studying the dynamics below the Earth’s surface. Image Credit: FAU.
In his 30-year career as a computer scientist, applied mathematician, and professor, Ulrich Rüde has worked with scientists and engineers from many different research backgrounds, helping them use simulation in their work as efficiently as possible. Regardless of the science domain, though, Rüde knows that researchers want to spend most of their time solving science problems rather than figuring out how to best compile or port their respective codes to a specific high-performance computing (HPC) environment.
Rüde and his closest collaborators work on the frontiers of computer science. Recently, for example, he helped a team from his home university, the Friedrich Alexander University Erlangen-Nuremberg (FAU) and researchers at the Technical University of Munich (TUM) to solve the largest-ever finite element system on a supercomputer. The calculation included more than 10 trillion (1013) unknowns in the simulation, requiring 80 terabytes of data for the solution vector alone. Finite element systems are central to many computational engineering and science applications.
Rüde has also recently collaborated with numerical analysts from TUM and geophysicists from the Ludwig Maximillians University Munich (LMU) in using Gauss Centre for Supercomputing (GCS) high-performance computing (HPC) resources at the Leibniz Supercomputing Centre (LRZ), the Jülich Supercomputing Centre (JSC), and the High-Performance Computing Center Stuttgart (HLRS). His collaborations have focused on developing new codes for studying the dynamics below the Earth’s surface. Specifically, the team is studying mantle convection, the process through which the Earth’s mantle moves. Such motion, driven by enormous subsurface pressures and forces, takes place at speeds of centimeters per year, and can eventually lead to the formation of mountains and earthquakes.
As the GCS centres transition to computing architectures that are scaling toward exascale computing—that is, computers capable of at least one quintillion (a 1 followed by 18 zeroes) calculations per second—we spoke with Prof. Rüde to get his thoughts on the challenges and the promises of the future of HPC.

Prof. Dr. Ulrich Rüde of Friedrich Alexander Universität Erlangen-Nürnberg.
GCS: Prof. Rüde, as a computer scientist you have focused on HPC, but have never restricted your work to a single application. What advantages does this provide in terms of solving problems of efficiency, scalability, and portability?
UR: Computer science expertise is necessary to design the application frameworks of the future. Those who are coming from an application background or mathematics alone often do not have knowledge about computer architectures and algorithms; they often lack expertise in software engineering. When working with a research team, we try to pull in a lot of technology, whether that is advanced algorithms, compilers, performance engineering, or novel code generation techniques.
Of course, some disciplines have invested heavily in these directions as well, but our work is special, as we approach applications not purely in terms of code development. We want to understand the application and the models behind it, and to find the most efficient algorithms that serve the needs of the target discipline. Computational science is the combination of all of these things. It is neither a sub-branch of the target discipline, nor mathematics, nor computer science. We create new HPC simulation methods by integrating all these components.
GCS: Why do you think science needs exascale computing, and what do you see as the biggest challenges associated with being ready for exascale?
UR: One example that illustrates the need for exascale computing can be seen in geophysics applications such as the ones I have been working on recently, which rely on a lot of uncertain data. Ideally we would like to resolve the whole planet with 1-kilometre resolution. But since Earth has a volume of one trillion (1012) cubic kilometres, this would mean using computational meshes in our simulations with this many cells. In every time step a system of this size must then be solved, which is an enormous undertaking. To handle the uncertainties of available input data and the need to compute backwards in time, we will need even more computing power. For this reason, I would say that exascale is the next step, but it is not the last step.
In my view, one of the biggest challenges to exascale stems from the shift in architectures from classical CPU-only models to accelerator-based architectures. I have been involved in several projects about exascale computing preparedness, for example under the auspices of the DFG priority program SPPEXA, but what I often see is that, despite talking about how exascale is fundamentally different from what we have been doing, most projects are making incremental changes to their codes. New architectures can demand significant reworking of codes, and people understand that if they have an old code, they need to do something about it, but hardly anyone is starting to write completely new code.
The end of Moore’s Law [a 1960s-era theory noting that the number of transistors on a circuit board was doubling every year, leading to a steady, exponential increase in computing power] may lead to a more fundamental shift in computing than exascale. To use an analogy from economics, we have developed HPC applications in a state of constant deflation. We haven’t spent as much effort developing better algorithms because next-generation hardware will seemingly always be cheaper and faster than the current generation. Some people think there will be a replacement for Moore’s Law, such as quantum computing or another avenue, but I think computer science is going to become more like traditional engineering fields, where much more effort must be put into making the most efficient use of the resources that are available, even when the gains are only modest.
GCS: What do computing centres, such as the GCS member centres, need to be doing to support their users during this transitional period in HPC?
UR: First of all, I think that in terms of access to computing power, we have been doing well in Germany. Due to demand, researchers may not always get as much time as they hope for, but we have up-to-date machines and researchers can focus on their work. The GCS centres also seem to work well together, and I think it helps to have the centres taking turns when it comes to investments in hardware. Our goal should always be to have all relevant architectures at an internationally competitive level. And efforts must be undertaken to stay competitive with what is happening in the USA and Asia.
If I am right in my thinking about the end of Moore’s Law, though, the centres are going to have to make a bigger shift to focusing on software and algorithms rather than hardware. The distributed research funding in Europe means that often a lot of money goes into method and code development, but if nothing else happens and, for example, a project isn’t renewed, then the knowledge gained over the course of the project can get lost. In the coming years an alliance of HPC centres and GCS must develop a new kind of infrastructure to support further developing software and retaining the knowledge base that went into the development of scientific software. This is a very fundamental issue that will only be resolved through a combined effort of research institutes, computer centres, and funding institutions. I see an increasing awareness of the problem, but not yet a good solution. There are many focused application communities that could benefit from institutional support for HPC software sustainability.
-Interview by Eric Gedenk